Как безопасно и эффективно парсить изображения Google

Хотите услышать интересную статистику? По оценкам 136 миллиардов Проиндексированных изображений в Google Картинках. Это смехотворное количество, не так ли?
Независимо от того, собираете ли вы изображения для исследований, машинного обучения или цифрового маркетинга, возможность парсинга Google Images может быть невероятно полезной.
Однако скрейпинг в больших масштабах представляет различные технические проблемы, от защит Google от скрейпинга до запретов IP-адресов и ограничений скорости.
В этом руководстве мы рассмотрим все, что вам нужно знать о безопасном скрейпинге изображений Google, включая лучшие инструменты, лучшие практики и способы избежать блокировок, соблюдая при этом юридические аспекты.
Понимание извлечения изображений из Google
Скрейпинг изображений Google — это процесс программного извлечения изображений из результатов поиска Google.
Будь то исследование рынка, наборы данных для машинного обучения, анализ конкурентов или агрегация контента, извлечение данных из Google Images может обеспечить доступ к огромным объемам визуальных данных.
Однако, У Google строгие меры против скрейпинга, что делает необходимым следовать лучшим практикам, использовать правильные инструменты, и развернуть прокси-решения чтобы избежать обнаружения и блокировок.
Что означает парсинг изображений Google?
Скрейпинг Google Images относится к автоматизированному процессу извлечения URL-адресов изображений, метаданных или самих файлов изображений из результатов поиска Google.
This is typically done using веб-скрейпинг libraries like BeautifulSoup, Селен, или API которые облегчают извлечение структурированных данных.
Типичные варианты использования включают:
- Маркетинговые исследования: Сбор изображений для анализа трендов.
- Наборы данных машинного обученияОбучение ИИ-моделей с использованием размеченных изображений.
- E-commerceИзвлечение изображений продуктов для конкурентного анализа.
- Курирование контентаСбор визуального контента для блогов и социальных сетей.
Является ли скрейпинг Google Images законным?
Хотя сбор общедоступных данных сам по себе не является незаконным, Условия использования Google запрещают автоматизированный сбор без разрешения.
- Загрузка и использование изображений без должного указания авторства может привести к нарушению авторских прав.
- Google нанимает автоматизированные системы защиты такие как CAPTCHA и блокировка IP-адресов для предотвращения скрейпинга.
- Используя API поиска Google является законной и этичной альтернативой.
Крайне важно следовать лучшим практикам и обеспечивать соблюдение законов об использовании данных.
Инструменты и методы для сбора данных из Google Images
Существует несколько методов извлечения данных из Google Images, каждый из которых имеет разную степень сложности и эффективности.
С помощью Python и BeautifulSoup
BeautifulSoup — это легкая и эффективная библиотека для парсинга HTML-страниц. Вот простой скрипт на Python для извлечения URL-адресов изображений из Google Images:
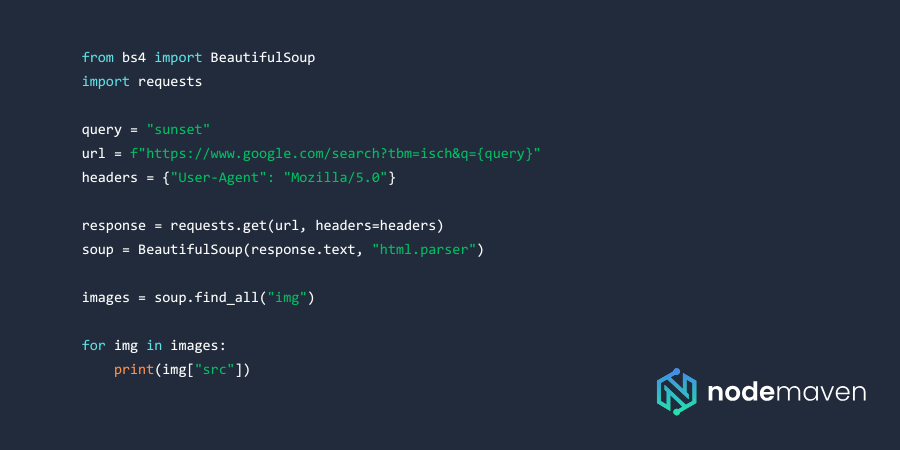
Однако Google затрудняет прямое извлечение данных, размывая результаты поиска изображений.
Автоматизация скрейпинга изображений с помощью Selenium
Selenium автоматизирует взаимодействие с браузером, позволяя обходить элементы, отрисованные с помощью JavaScript. Вот как вы можете автоматизировать прокрутку и загрузку изображений:
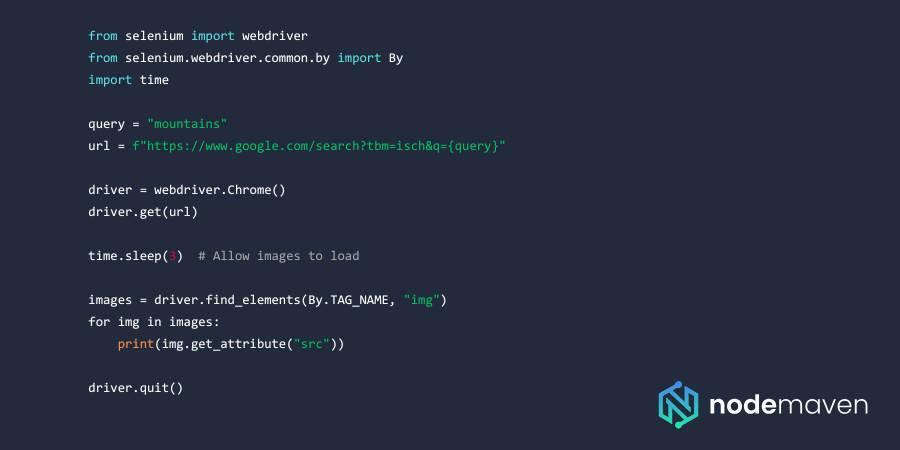
Selenium полезен для работы с динамическим содержимым, но он медленнее, чем решения на основе API.
API для скрейпинга Google Картинки
Если вам нужны структурированные и надежные результаты поиска изображений, API поиска Google Custom Search является законной альтернативой.
- Предлагает высокую точность и не требует разбора.
- Требуется ключ API и имеет ограничения на использование.
- Нет риска блокировки IP по сравнению с прямым скрейпингом.
Лучшие практики для эффективного скрейпинга изображений
Успешный скрейпинг Google Images требует стратегий для избежания обнаружения и повышения эффективности.
Избежание CAPTCHA и ограничений скорости
Google обнаруживает необычную активность из-за повторяющихся запросов. Чтобы избежать ограничения скорости:
- Добавить задержки между запросами.
- Рандомизировать пользовательские агенты для имитации человеческого просмотра.
- Использовать разные прокси Для распределения трафика.
Использование прокси-ротации для масштабного скрейпинга
Google активно блокирует повторяющиеся запросы с того же IP.
- Статические резидентские прокси полезны для поддержания единой идентичности.
- Ротационные резидентские прокси предоставлять свежие IP-адреса, делая их сложнее обнаружить.
- Датацентровые прокси обеспечивают скорость, но снижают анонимность, что делает их менее подходящими для масштабного скрейпинга.
Управление хранением и организацией данных
Обработка тысячи изображений требуется надлежащее Организация и преобразование.
- Сохранить изображения в организованные каталоги на основе категорий.
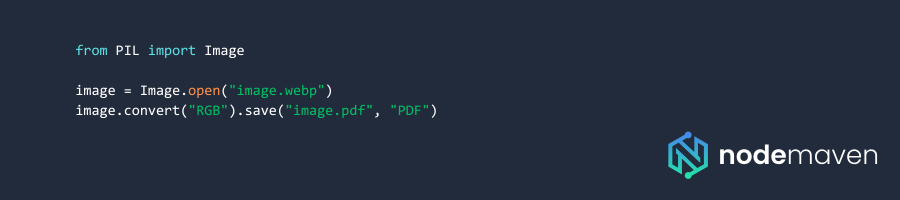
- Преобразовать форматы с помощью Скрипты Python, такие как WebP в PDF с помощью Python на пакетная обработка собранных изображений.
Пример кода на Python для WebP в PDF с помощью Python:
Распространенные трудности и способы их преодоления
Масштабный скрейпинг — задача не из простых. Google имеет мощные механизмы защиты от скрейпинга.
Меры Google против скрейпинга
Google использует несколько уровней защиты от ботов:
- ReCAPTCHAТребует ручной проверки.
- Отслеживание IP Блокирует IP-адреса, совершающие слишком много запросов.
- JavaScript-вызовы: Запутывает контент для нечеловеческих пользователей.
Решение: Используйте ротационные резидентские прокси для распределения запросов по множеству реальных IP-адресов.
Обработка блокировок и запретов IP-адресов
Если Google заблокирует ваш IP-адрес, вы не сможете получить доступ к поиску изображений.
- Используйте резидентские прокси для обхода обнаружения.
- Регулярно меняйте пользовательские агенты.
- Уменьшите частоту скрейпинга, чтобы не вызывать срабатывание служебных сигналов.
Решение: Используйте ротационные резидентские прокси, реализуйте ротацию IP-адресов, ограничивайте скорость запросов и используйте правильные заголовки для предотвращения и обхода блокировок IP-адресов при веб-скрейпинге изображений Google.
Парсинг Google Images в больших масштабах с помощью прокси NodeMaven
При скрейпинге Google Images, имея премиум прокси крайне важно избегать блокировок, обходить ограничения частоты запросов и максимизировать эффективность.
NodeMaven предлагает набор мощных резидентский прокси решения, разработанные для необнаруживаемого, масштабного веб-скрейпинга.
Почему стоит выбрать NodeMaven для скрейпинга изображений Google?
- Ротационные резидентские прокси для максимальной анонимности
- Автоматически переключайте IP-адреса, чтобы избежать ограничений скорости и капчи Google.
- Имитируйте реальное пользовательское поведение с разнообразными IP-адресами из обычных резидентских сетей.
- Статические резидентские прокси для долгосрочной стабильности
- Поддерживать стабильный IP для задач, требующих сохранения сессии.
- Идеально подходит для скрейпинга Google Images без частых переподключений или подозрительной активности.
- Высокоскоростная прокси-инфраструктура с низкой задержкой
- Оптимизированные прокси-серверы гарантируют, что вы получите быстрый поиск изображений не замедляя работу.
- Сократите количество неудачных запросов и повысьте эффективность скрейпинга с помощью 99.9% аптайм.
- Геотаргетированные прокси для скрейпинга по конкретным локациям
- Доступ изображения с региональными ограничениями из любой страны или города.
- Улучшение локализованных исследований и собрать географически релевантные данные изображений.
- Удобное управление прокси и круглосуточная поддержка
- Легко интегрируйте прокси NodeMaven с Selenium, BeautifulSoup или API.
- Получить круглосуточная поддержка от отраслевых экспертов для оптимизации
Используя премиум-прокси NodeMaven, вы можете эффективно парсить изображения Google, не беспокоясь о блокировке IP-адресов или ограничениях скорости.
Зарегистрируйтесь на NodeMaven сегодня получить высокопроизводительные резидентские прокси и Легко извлекайте данные из Google Images!


