Как выполнить веб-скрейпинг таблицы в Python [Без API для скрейпинга]

Интернет полон ценных данных, большая часть которых структурирована в таблицы на веб-сайтах.
Whether you’re a data analyst, researcher, or business owner, extracting table data can be essential for insights, automation, or competitive analysis. Instead of copying information manually, веб-скрейпинг lets you automate data collection with Python.
В этом руководстве мы рассмотрим, как извлекать данные из веб-таблиц с помощью Python: от настройки среды до решения реальных задач, таких как таблицы, отображаемые JavaScript, и блокировка IP-адресов.
Понимание веб-скрейпинга и его применений
Прежде чем углубляться в технические детали, давайте кратко разберемся, что такое веб-скрейпинг и зачем он нужен.
Веб-скрейпинг — это автоматизированный процесс извлечения данных с веб-сайтов. Вместо ручного копирования и вставки информации, скрипт на Python может получить, разобрать и сохранить большие объемы структурированных данных эффективно.
По своей сути, веб-скрейпинг имитирует просмотр сайтов человеком но в гораздо более быстром и автоматизированном масштабе.
Однако, поскольку некоторые веб-сайты ограничивают скрейпинг данных для предотвращения злоупотреблений, компании и частные лица должны соблюдать этические нормы и использовать правильные технологии, чтобы избежать обнаружения.
Как веб-скрейпинг используется в различных отраслях
Веб-скрейпинг широко используется в различных отраслях для принятия решений на основе данных:
- Электронная коммерция и розничная торговля: Отслеживайте цены конкурентов, наличие товаров и анализируйте отзывы клиентов для получения бизнес-инсайтов.
- SEO и цифровой маркетинг: Собирайте результаты поиска для отслеживания позиций по ключевым словам, профилей обратных ссылок и рекламных объявлений.
- Финансовые услуги: Извлеките цены акций, значения криптовалют или экономические показатели для финансового анализа.
- Мониторинг социальных сетей: Собирайте данные из Instagram, Twitter или Reddit для анализа тенденций вовлеченности, анализа настроений или упоминаний бренда.
- Исследование рынка труда: Скребок список вакансий с таких сайтов, как LinkedIn или Indeed, для отслеживания тенденций в найме.
Правовые и этические аспекты веб-скрейпинга
Хотя веб-скрейпинг — это мощный инструмент, важно оставаться в рамках законных и этических норм:
- Проверить файл “robots.txt” веб-сайта: Этот документ указывает парсерам, какие страницы разрешены/запрещены для сканирования.
- Соблюдайте лимиты скорости веб-сайта: Избегайте отправки чрезмерных запросов, которые могут нарушить работу веб-сайта.
- Избегайте сбора личных данныхСбор персональных данных (PII) может привести к юридическим последствиям.
- Используйте качественные проксиДля предотвращения блокировки по IP и обеспечения анонимности при скрейпинге.
Принимая во внимание эти соображения, давайте рассмотрим, как эффективно парсить веб-таблицы в Python.
Зачем извлекать данные из таблиц?
Таблицы на веб-сайтах содержат структурированные данные, что делает их идеальными для:
- Маркетинговые исследованияИзвлечение ценовой информации конкурентов, тенденций и отзывов клиентов.
- Проекты по науке о данных: Соберите наборы данных для моделей машинного обучения.
- SEO-мониторинг: Собирайте рейтинги ключевых слов, метаданные и результаты поиска.
- Финансовый анализСобирайте цены акций, данные о криптовалютах или финансовую отчетность.
- Инсайты электронной коммерцииОтслеживание товарных позиций, цен и отзывов.
Однако, Не все веб-сайты разрешают скрейпинг, а некоторые применяют меры безопасности, такие как запрет по IP. Мы рассмотрим как избежать обнаружения с помощью прокси далее в этом руководстве.
Настройка Вашего Окружения для Веб-Скрэпинга
Прежде чем вы сможете извлекать таблицы, вам понадобится Настройте свою среду Python и установить несколько ключевых библиотек.
Установка необходимых библиотек
Для веб-скрейпинга таблиц в Python обычно используются следующие библиотеки:
- BeautifulSoupИзвлекает данные из HTML-страниц.
- ЗапросыОтправляет HTTP-запросы для получения содержимого веб-страницы.
- Pandas
- Сохраняет собранные данные в структурированных форматах, таких как CSV или DataFrame.
- СеленИзвлекает динамические таблицы, отображаемые с помощью JavaScript.
Установите их с помощью pip:
pip install beautifulsoup4 requests pandas selenium
Понимание структуры HTML-таблиц
Таблицы в HTML структурируются с помощью Вот простая HTML-таблица: Ваш Python скрипт должен найти Как только ваша среда будет готова, давайте рассмотрим различные методы для извлечь данные таблицы с веб-сайтов. BeautifulSoup — один из самых простых способов парсить таблицы, когда JavaScript не вовлеченный. Pandas упрощает извлечение таблиц, когда таблицы структурированы правильно: Если таблица загружена с помощью JavaScript, BeautifulSoup не сработает. Вместо этого, использовать Selenium для автоматизации взаимодействия с браузером: Веб-скрейпинг не всегда прост. Веб-сайты применяют различные меры для обнаружения и блокировки скраперов. Вот как справиться с наиболее распространенными проблемами. При масштабном скрейпинге с нашем браузер для скрейпинга, веб-сайты могут обнаружить ваш IP-адрес и заблокировать его. Вот тут-то и резидентский прокси Помощь. Используя прокси для веб-скрейпинга убедитесь, что ваши скрипты остаются незамеченными и успешными. Веб-скрейпинг таблиц в Python — мощный метод, будь то анализ финансовые данные, аналитика социальных сетей или рыночные тенденции. С помощью BeautifulSoup, Pandas и Selenium, вы можете эффективно извлекать табличные данные с веб-сайтов. К избежать блокировок IP и максимизировать успех скрейпинга, интегрируя резидентские прокси от NodeMaven это лучшее решение. Зарегистрируйтесь сегодня и расширьте возможности своих проектов по веб-скрейпингу с помощью безопасных и надежных прокси! 🚀,
(строка таблицы), и элементы. 
тег, пройтись циклом
строки, и извлечь ценности. Извлечение данных таблицы с помощью Python
Веб-скрейпинг с BeautifulSoup
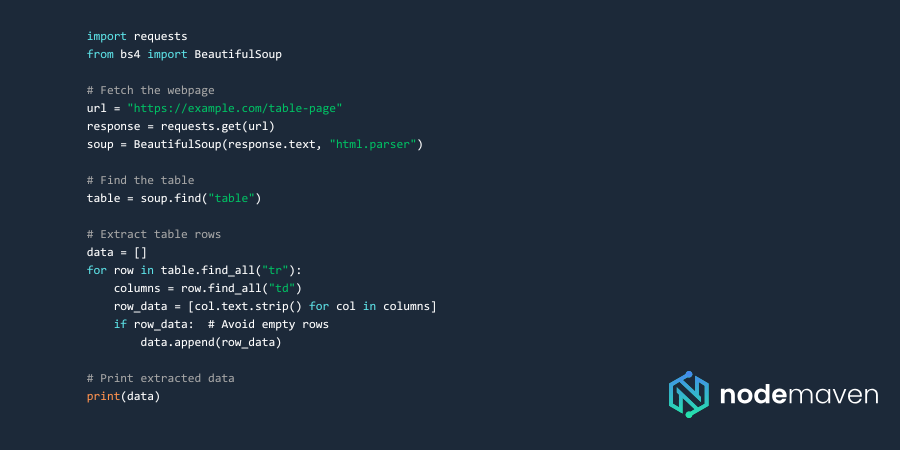
Веб-скрейпинг с Pandas
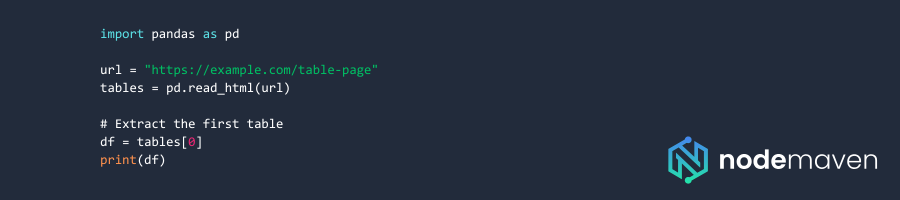
Веб-скрейпинг динамических таблиц с помощью Selenium
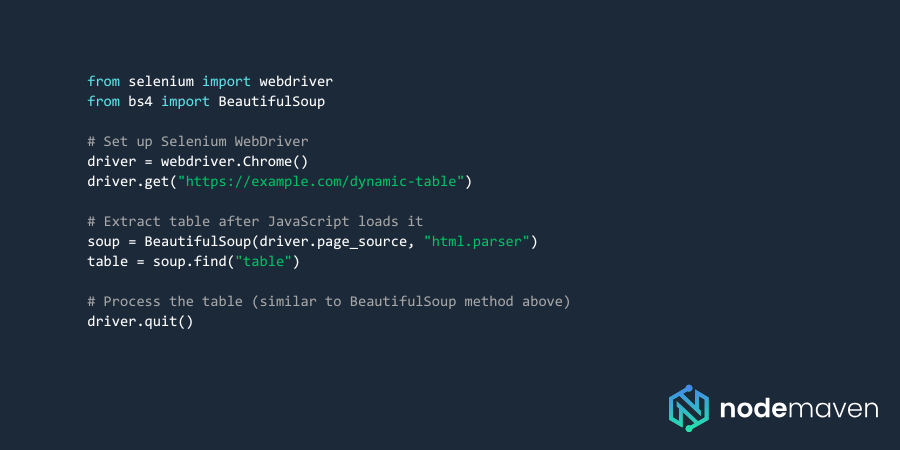
Обработка распространенных проблем при извлечении данных из таблиц
Вызов 1: Таблицы, отображаемые JavaScript
Задача 2: Блокировка IP-адресов и ограничение скорости
Испытание 3: Капчи и антиботы
Масштабируйте свой бизнес с помощью браузера для скрейпинга NodeMaven
Зачем использовать прокси NodeMaven?
Вам также могут понравиться эти статьи
![]()


