How to Scrape Google Images Safely and Efficiently

Want to hear interesting stats? There are an estimated 136 billion indexed images on Google Image Search. That’s a ridiculous amount, right?
Whether you’re gathering images for research, machine learning, or digital marketing, the ability to scrape Google Images can be incredibly useful.
However, scraping at scale presents various technical challenges, from Google’s anti-scraping protections to IP bans and rate limits.
In this guide, we’ll cover everything you need to know about scraping Google Images safely, including the best tools, best practices, and how to avoid blocks while complying with legal considerations.
Understanding Google Image Scraping
Google Image Scraping is the process of programmatically extracting images from Google’s search results.
Whether for market research, machine learning datasets, competitor analysis, or content aggregation, scraping Google Images can provide access to vast amounts of visual data.
However, Google has strict anti-scraping measures, making it essential to follow best practices, use the right tools, and deploy proxy solutions to avoid detection and bans.
What Does It Mean to Scrape Google Images?
Scraping Google Images refers to the automated process of extracting image URLs, metadata, or actual image files from Google’s search results.
This is typically done using web scraping libraries like BeautifulSoup, Selenium, or APIs that facilitate structured data extraction.
Common use cases include:
- Market research: Gathering images for trend analysis.
- Machine learning datasets: Training AI models with labeled images.
- E-commerce: Extracting product images for competitive analysis.
- Content curation: Collecting visual content for blogs and social media.
Is Scraping Google Images Legal?
While scraping public data isn’t inherently illegal, Google’s Terms of Service prohibit automated scraping without permission.
- Downloading and using images without proper attribution may lead to copyright violations.
- Google employs automated defenses like CAPTCHAs and IP bans to discourage scraping.
- Using Google’s Custom Search API is a legal and ethical alternative.
It’s crucial to follow best practices and secure compliance with data usage laws.
Tools and Methods to Scrape Google Images
There are multiple methods to scrape Google Images, each with varying levels of complexity and effectiveness.
Using Python and BeautifulSoup
BeautifulSoup is a lightweight and efficient library for parsing HTML pages. Here’s a simple Python script to extract image URLs from Google Images:
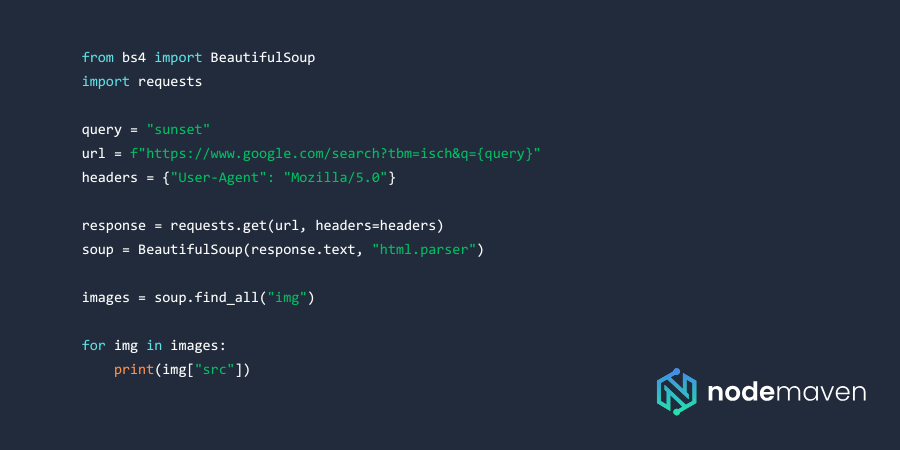
However, Google makes direct scraping harder, by blurring the image search results.
Automating Image Scraping with Selenium
Selenium automates browser interactions, allowing it to bypass JavaScript-rendered elements. Here’s how you can automate scrolling and downloading images:
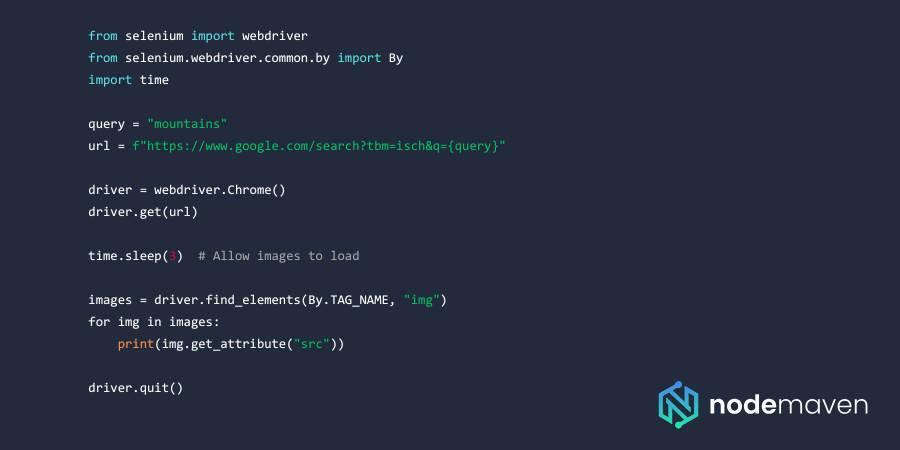
Selenium is useful for handling dynamic content, but it’s slower than API-based solutions.
APIs for Google Image Scraping
If you need structured and reliable image search results, Google’s Custom Search API is a legal alternative.
- Offers high accuracy and doesn’t require parsing.
- Requires an API key and comes with usage limits.
- No risk of IP bans compared to direct scraping.
Best Practices for Efficient Image Scraping
Scraping Google Images successfully requires strategies to avoid detection and maximize efficiency.
Avoiding CAPTCHA and Rate Limits
Google detects unusual activity from repeated queries. To prevent rate limits:
- Add time delays between requests.
- Randomize user agents to simulate human browsing.
- Use different proxies to distribute traffic.
Using Proxy Rotation for Large-Scale Scraping
Google actively blocks repeated requests from the same IP.
- Static residential proxies are useful for maintaining a consistent identity.
- Rotating residential proxies provide fresh IPs, making them harder to detect.
- Datacenter proxies offer speed but lower anonymity, making them less ideal for large-scale scraping.
Managing Data Storage and Organization
Handling thousands of images requires proper organization and conversion.
- Save images in organized directories based on categories.
- Convert formats using Python scripts, such as WebP to PDF with Python for batch processing of scraped images.
Example Python code for WebP to PDF with Python:
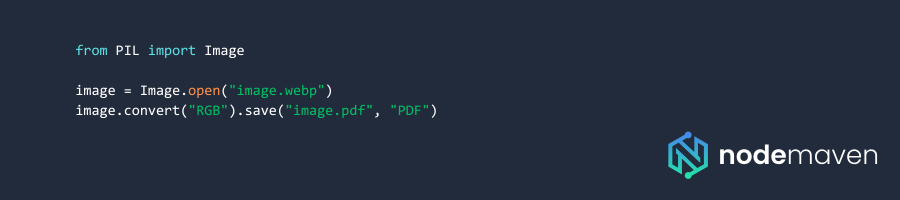
Common Challenges and How to Overcome Them
Scraping at scale isn’t easy. Google has strong anti-scraping mechanisms in place.
Google’s Anti-Scraping Measures
Google employs multiple layers of anti-bot protection:
- ReCAPTCHA: Requires manual verification.
- IP tracking: Blocks IPs making too many requests.
- JavaScript challenges: Obfuscates content for non-human users.
Solution: Use rotating residential proxies to distribute requests across multiple real IPs.
Handling IP Blocks and Bans
If Google bans your IP, you won’t be able to access image search.
- Use residential proxies to bypass detection.
- Switch user agents regularly.
- Reduce the scraping frequency to avoid triggering security flags.
Solution: Use rotating residential proxies, implement IP rotation, throttle request rates, and use proper headers to prevent and overcome IP blocks while scraping Google Images.
Scrape Google Images at Scale with NodeMaven Proxies
When scraping Google Images, having premium proxies is essential to avoid bans, bypass rate limits, and maximize efficiency.
NodeMaven offers a suite of powerful residential proxy solutions designed for undetected, large-scale web scraping.
Why Choose NodeMaven for Google Image Scraping?
- Rotating residential proxies for maximum anonymity
- Automatically switch IPs to avoid Google’s rate limits and CAPTCHAs.
- Mimic real user behavior with diverse IP addresses from legitimate residential networks.
- Static residential proxies for long-term stability
- Maintain a consistent IP for tasks that require session persistence.
- Perfect for scraping Google Images without frequent reconnections or suspicious activity.
- High-speed, low-latency proxy infrastructure
- Optimized proxy servers make sure that you get fast image retrieval without slowing down operations.
- Reduce request failures and increase scraping efficiency with 99.9% uptime.
- Geo-targeted proxies for location-specific scraping
- Access region-restricted image results from any country or city.
- Improve localized research and gather geographically relevant image data.
- User-friendly proxy management & 24/7 support
- Easily integrate NodeMaven proxies with Selenium, BeautifulSoup, or APIs.
- Get round-the-clock support from industry experts to optimize
Using NodeMaven’s premium proxies, you can scrape Google Images efficiently without worrying about IP bans or rate limits.
Sign up for NodeMaven today to get high-performance residential proxies and scrape Google Images with ease!



