How to Web Scrape a Table in Python [Without a Scraping API]

The internet is packed with valuable data, much of it structured in tables on websites.
Whether you’re a data analyst, researcher, or business owner, extracting table data can be essential for insights, automation, or competitive analysis. Instead of copying information manually, web scraping lets you automate data collection with Python.
In this guide, we’ll explore how to web scrape a table in Python, from setting up your environment to handling real-world challenges like JavaScript-rendered tables and IP blocking.
Understanding Web Scraping and Its Applications
Before diving into the technical details, let’s briefly understand what web scraping is and why it’s useful.
Web scraping is the automated process of extracting data from websites. Instead of manually copying and pasting information, a Python script can fetch, parse, and store large amounts of structured data efficiently.
At its core, web scraping mimics human browsing but at a much faster and automated scale.
However, since some websites restrict scraping to prevent data misuse, businesses and individuals must follow ethical guidelines and use the right technologies to avoid detection.
How Web Scraping is Used Across Industries
Web scraping is widely used in multiple industries for data-driven decision-making:
- E-commerce & retail: Monitor competitor pricing, track product availability, and analyze customer reviews for business insights.
- SEO & digital marketing: Scrape search engine results to track keyword rankings, backlink profiles, and ad placements.
- Financial services: Extract stock market prices, cryptocurrency values, or economic indicators for financial analysis.
- Social media monitoring: Collect data from Instagram, Twitter, or Reddit to analyze engagement trends, sentiment analysis, or brand mentions.
- Job market research: Scrape job listings from websites like LinkedIn or Indeed to track hiring trends.
Legal and Ethical Considerations in Web Scraping
While web scraping is powerful, it’s essential to stay within legal and ethical boundaries:
- Check a website’s “robots.txt” file: This document tells scrapers which pages are allowed/disallowed for scraping.
- Respect website rate limits: Avoid sending excessive requests that may disrupt a website’s performance.
- Avoid scraping personal data: Collecting personally identifiable information (PII) can lead to legal consequences.
- Use quality proxies: To prevent IP bans and secure anonymity while scraping.
With these considerations in mind, let’s dive into how to web scrape a table in Python effectively.
Why Scrape Table Data?
Tables on websites contain structured data, making them ideal for:
- Market research: Extract competitor pricing, trends, and customer reviews.
- Data science projects: Gather datasets for machine learning models.
- SEO monitoring: Scrape keyword rankings, metadata, and search results.
- Financial analysis: Collect stock prices, cryptocurrency data, or financial statements.
- E-commerce insights: Track product listings, prices, and reviews.
However, not all websites allow scraping, and some implement security measures like IP bans. We’ll cover how to avoid detection using proxies later in this guide.
Setting Up Your Environment for Web Scraping
Before you can scrape tables, you’ll need to set up your Python environment and install a few key libraries.
Installing Required Libraries
To web scrape a table in Python, you’ll typically use the following libraries:
- BeautifulSoup: Extracts data from HTML pages.
- Requests: Sends HTTP requests to fetch webpage content.
- Pandas: Stores scraped data in structured formats like CSV or DataFrames.
- Selenium: Scrapes dynamic tables rendered with JavaScript.
Install them using pip:
pip install beautifulsoup4 requests pandas selenium
Understanding HTML Structure of Tables
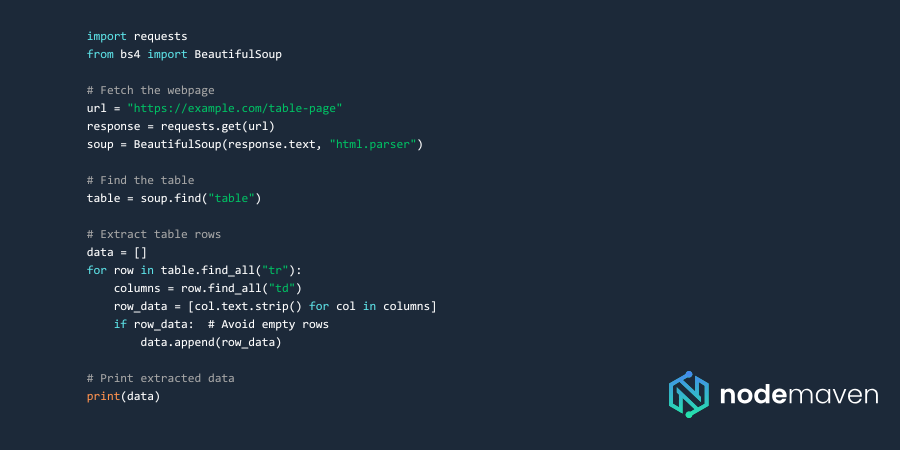
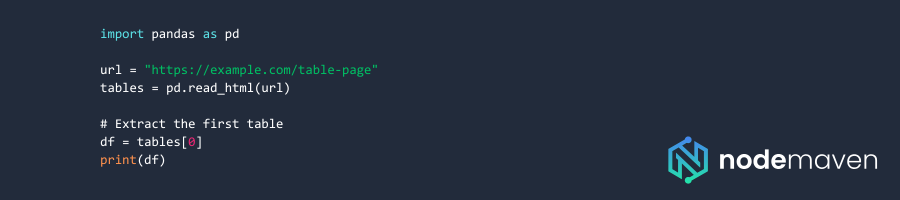
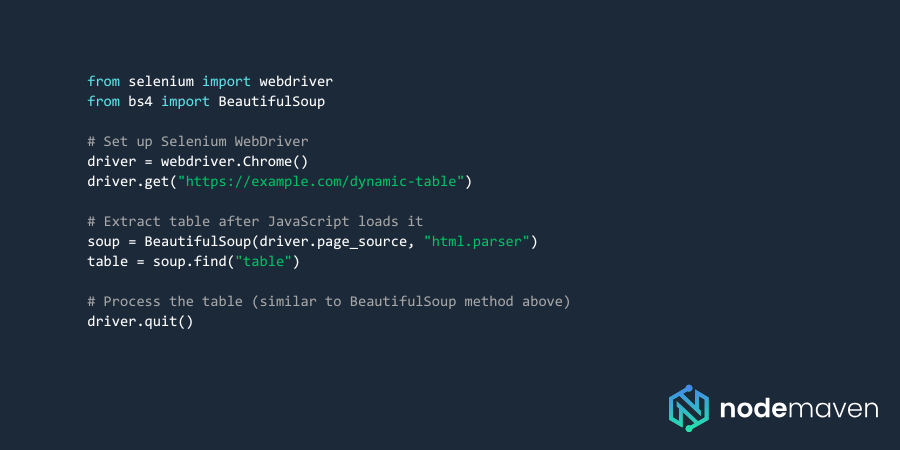
Tables in HTML are structured using Here’s a simple HTML table: Your Python script needs to find the Once your environment is ready, let’s explore different methods to extract table data from websites. BeautifulSoup is one of the easiest ways to scrape tables when JavaScript is not involved. Pandas simplifies table extraction when tables are structured correctly: If a table is loaded with JavaScript, BeautifulSoup won’t work. Instead, use Selenium to automate browser interaction: Web scraping isn’t always straightforward. Websites employ various measures to detect and block scrapers. Here’s how to tackle the most common challenges. When scraping at scale with our scraping browser, websites may detect and block your IP. That’s where residential proxies help. Using proxies for web scraping makes sure your scripts remain undetected and successful. Web scraping tables in Python is a powerful technique, whether you’re analyzing financial data, social media insights, or market trends. By using BeautifulSoup, Pandas, and Selenium, you can efficiently extract table data from websites. To avoid IP blocks and maximize scraping success, integrating residential proxies from NodeMaven is the best solution. Sign up today and supercharge your web scraping projects with secure and reliable proxies! 🚀,
(table row), and (table data) elements. 
tag, loop through
rows, and extract values. Extracting Table Data Using Python
Web Scraping with BeautifulSoup
Web Scraping with Pandas
Web Scraping with Selenium for Dynamic Tables
Handling Common Challenges in Table Scraping
Challenge 1: JavaScript-Rendered Tables
Challenge 2: IP Blocking and Rate Limiting
Challenge 3: Captchas and Anti-Bot Systems
Scale Your Business with NodeMaven Scraping Browser
Why Use NodeMaven’s Proxies?
You might also like these articles
![]()


